
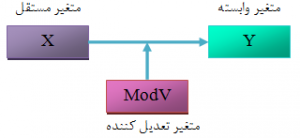
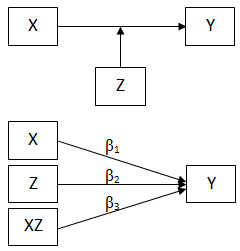
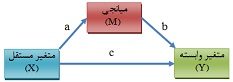
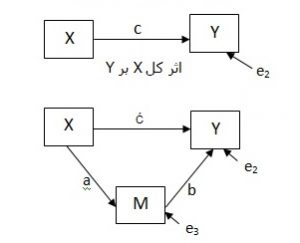



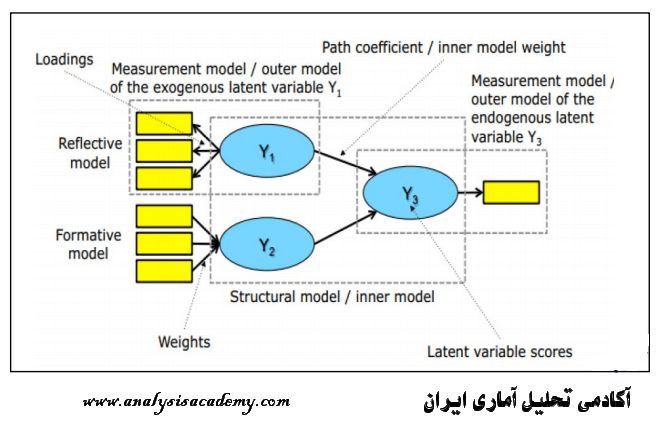

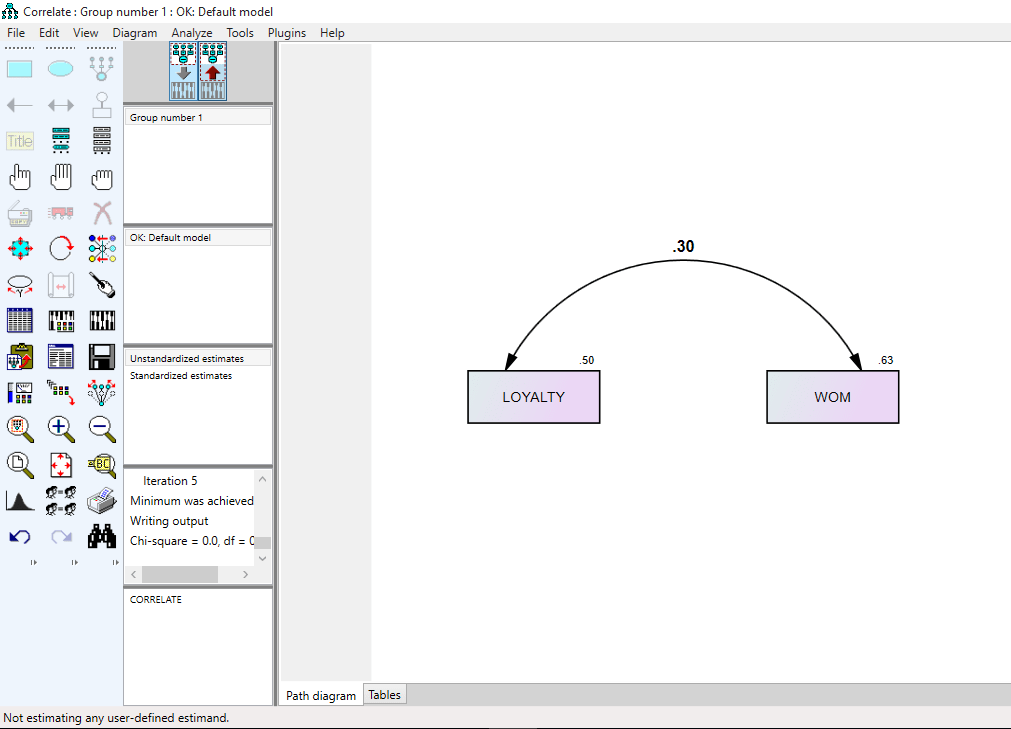
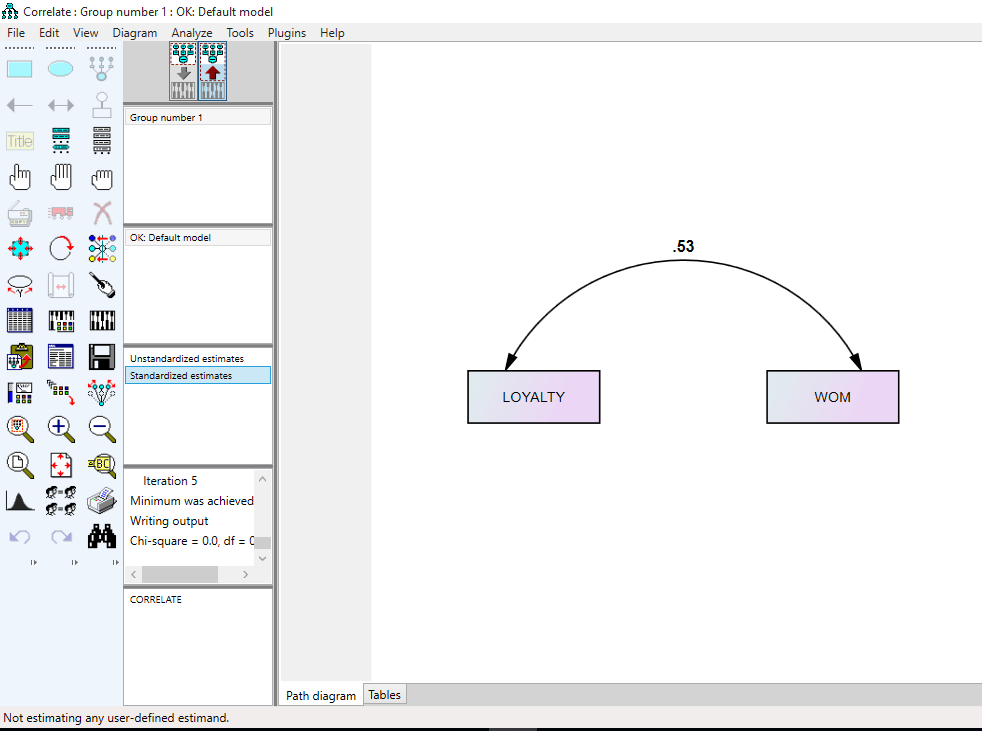
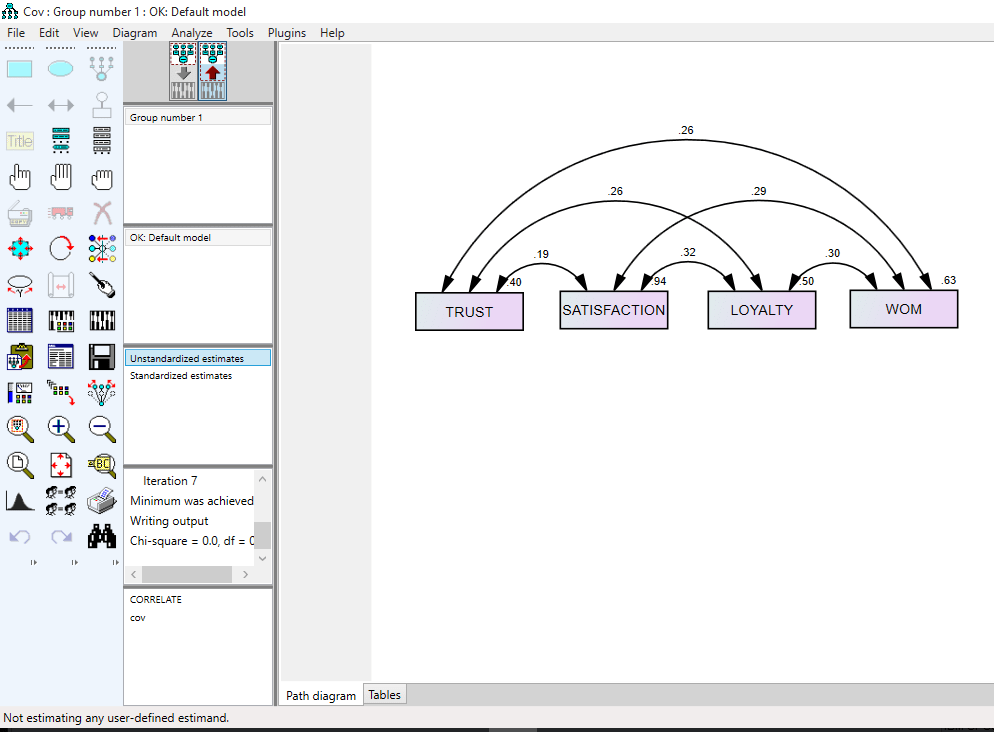
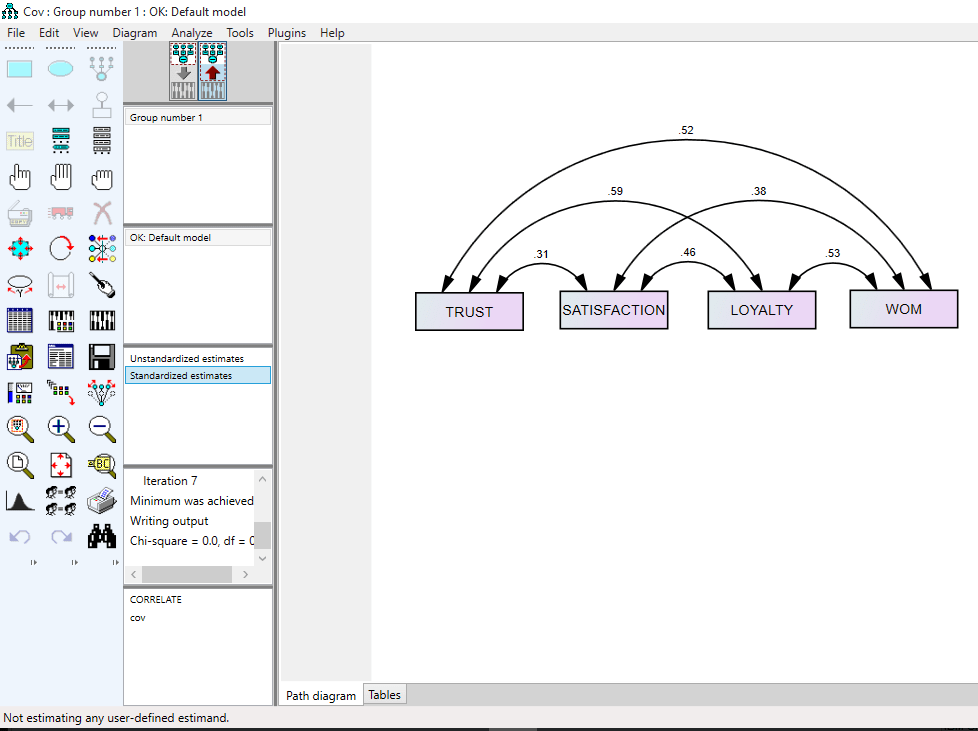
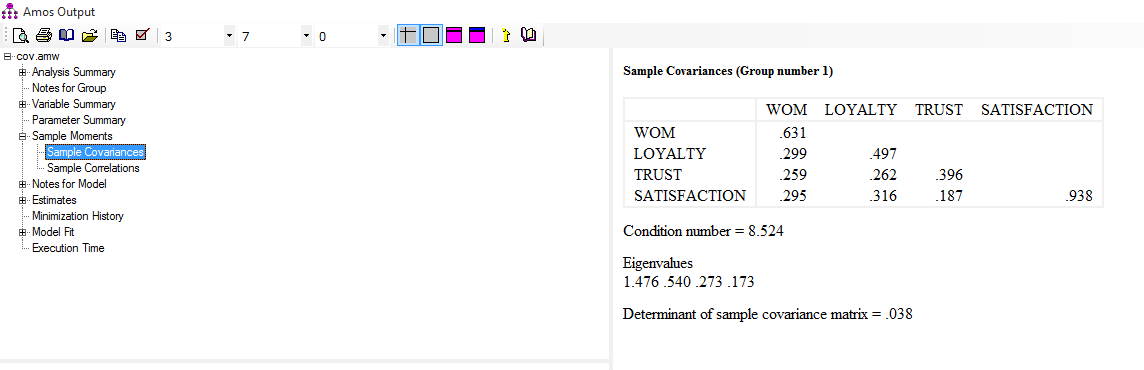
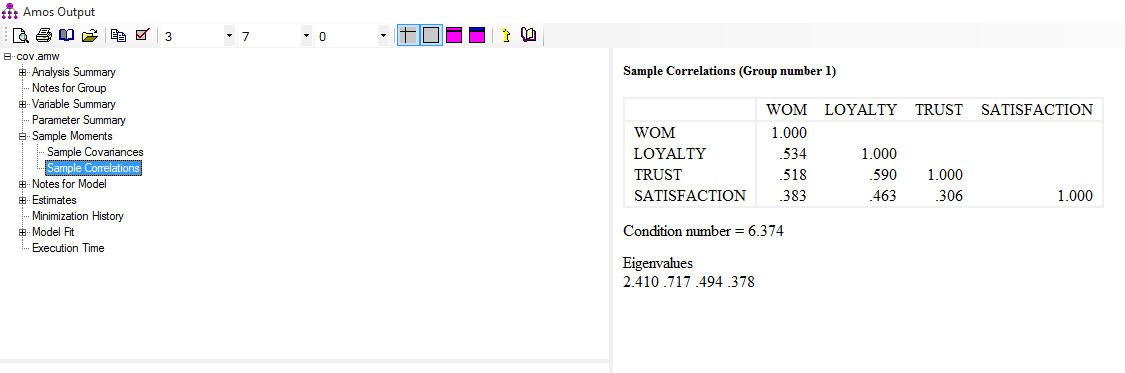



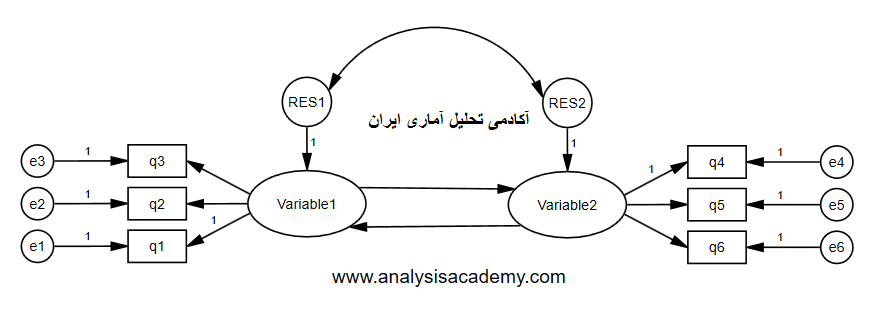
تحلیل PLS توسط هرمن ولد ابداع شده است. تفاوت این روش شناسی نسبت به CBSEM در این است که به جای استفاده از متغیرهای مکنون، با بلوکی ازمتغیرهای مشتق شده از ترکیبات وزنی متغیرهای مشاهده شده کار میکند. به همین دلیل خود آنها هم قابل مشاهده اند. رویکرد تخمینی PLS ، ااماً متشکل از یک توالی تکراری از رگرسیونهای OLS است که با یک تقریب خارجی آغازمیگردد، در اینجا متغیرهای مکنون مدل به وسیله ترکیب خطی معرفهایشان تقریب زده شده، و برای تعیین وزنهای مربوط به معرفهای انعکاسی و ترکیبی به ترتیب از تحلیل مولفه های اصلی و تحلیل رگرسیون استفاده میشود.
در مرحله بعد تقریب داخلی مقادیر جایگزین با استفاده از متوسط وزنی بلوکی از متغیرهای مجاور مدل ساختاری مشخص میشود. روشهای مختلفی برای تعریف مجاورت در طرحهای مختلف وزن دهی وجود دارد، اما آنچنان که بعدها مشاهده میکنیم نوع طرح انتخابی تاثیر کوچکی بر نتایج نهایی خواهد داشت. با تغییر وزنهای اولیه و ایجاد مقادیر تازه، استفاده از فرایند تقریب داخلی و خارجی تا آنجا تکرار میشود که مقادیر هر مورد به یکدیگر نزدیک شده و همگرایی حاصل شود.
تعداد معرفها در هر سازه و حجم نمونه
در تحلیل PLS ، برخلاف CBSEM به جای کار با متغیرهای مکنون از بلوکی از متغیرها استفاده می شود؛بلوکهایی که به صورت ترکیبی خطی از مجموعه معرفها بوده و خطای اندازه گیری مخصوص به خود را دارند.
پس باید نمرات تعیین شده برای هر بلوک از متغیرها، همچنین برای هر مورد و پارامترهای برآورد شده متناظر با آنها، متفاوت از یکدیگر باشند. این نمرات تنها زمانی به مقادیر واقعی جامعه نزدیک میشوند که تعداد معرفهای هر سازه و اندازه نمونه تا بینهایت افزایش یابد. بنابراین در شرایط واقعی روش شناسی PLS ، پارامترهای مدل ساختاری را کمتر از مقدار واقعی و پارامترهای مدل اندازه گیری را بیشتر از مقدار واقعی برآورد میکند.
اما در CBSEM انتظار میرود افزایش در حجم نمونه به کاهش واریانس پارامترها منجر شود. اگر تعداد خاصی از معرفها داشته باشیم افزایش نامحدود حجم نمونه موجب نا اریب شدن برآوردها نمیشود. ولی در اندازه خاصی از نمونه افزایش تعداد معرفهای هر سازه تنها میتواند منجر به کاهش بخشی از پراکندگی پارامترهای برآوردی گردد. در عوض تحلیل PLS بیشتر برای مواردی مناسب است که روش CBSEM در آنجا قابل اعمال نیست. مانند زمانی که تعداد معرفهای هر متغیر مکنون بینهایت زیاد یا حجم نمونه بسیار کوچک باشد.
اساس روش PLS به عنوان یک رویکرد منطبق بر اطلاعات محدود، مبتنی بر پیش فرضهای آماری آسان در ارتباط با ویژگی معرفهاست. از این رو در بیشتر موارد آن را نوعی تکنیک مدلسازی نرم می نامند تا از رویکرد مدلسازی سخت CBSEM متمایز شود. به ویژه که PLS تحت تاثیر توزیع یا مقیاس اندازه گیری معرفهای مورد استفاده قرار نمیگیرد و تنها ویژگی که باید برای تحلیل دادهها در این روششناسی برآورده شود، برابری بخش سیستماتیک تمام رگرسیونهای خطی OLS با امید ریاضی شرطی متغیرهای وابسته است.
این شرط که بیشتر اوقات تدوین پیش بین نامیده میشود، نشان میدهد که مدل درونی در حقیقت سیستمی از زنجیره علّی با پسماندهای غیر همبسته است، و پسماندهای متعلق به یک متغیر مکنون درونزای خاص با متغیرهای مکنون پیشبین متناظرشان رابطه ای غیر همبسته دارند. بسیاری از دانشمندان، پایایی پارامترهای برآورد شده برای دادهه ای غیر نرمال را در روش PLS با استفاده از تکنیک شبیه سازی مونت کارلو ثابت کرده اند.
در ارتباط با بارهای عاملی معرفهای موجود در مدلهای عاملی، همان نکاتی که پیشتر در موردCBSEM گفته شد در اینجا نیز صادق است. با این حال، برای کار با سازه هایی که به شکلی نادرست عملیاتی شده اند، روش PLS قویتر از رویکرد CBSEM است. رویکرد برآورد همزمان در روش شناسی CBSEM موجب شده است که وجود یک سازه ضعیف در مدل بر مقدار تمام پارامترهای برآورد شده و متغیرهای مکنون مدل تاثیر گذارد. در صورتی که روش PLS این عامل منفی بیشتر روی همان سازه و متغیرهایی که در مجاورت با آن قرار دارند اثر خواهد داشت.
منبع: https://analysisacademy.com





درباره این سایت